



System Design - Search Autocomplete System
Functional Requirements
- Suggest possible completions for a user's input.
- Return five popular autocomplete suggestions.
- Spell-check is not required.
- Support is required only for the English language.
Non-Functional Requirements
- Availability: The autocomplete service should be highly available and reliable.
- Latency: The system should exhibit low latency, ideally responding to user input within milliseconds.
- Scalability: The system should be capable of horizontal scaling to accommodate increases in data and user traffic
Capacity Requirements
- Assume there are 5 billion searches daily (50,000 searches per second).
- Assume there are around 100 million unique search terms.
- Assume each term consists of four words with five characters each (2 bytes per character).
This implies that each term requires 40 bytes of storage (4 words * 5 characters * 2 bytes). Consequently, it requires a total storage of 4GB (100 million terms * 40 bytes).
High Level Design
Approach 1
- Create a relational datastore and store each query and its frequency.
- When a new query is searched, increment the frequency count for the query.
- To generate autocomplete suggestions, run an SQL query on the table and retrieve the top five queries using the LIKE command.
Approach 2 (Preferred)
- Use the Trie data structure to store the queries.
- While retrieving suggestions based on a prefix, traverse the Trie to the last character and then identify the top suggested queries.
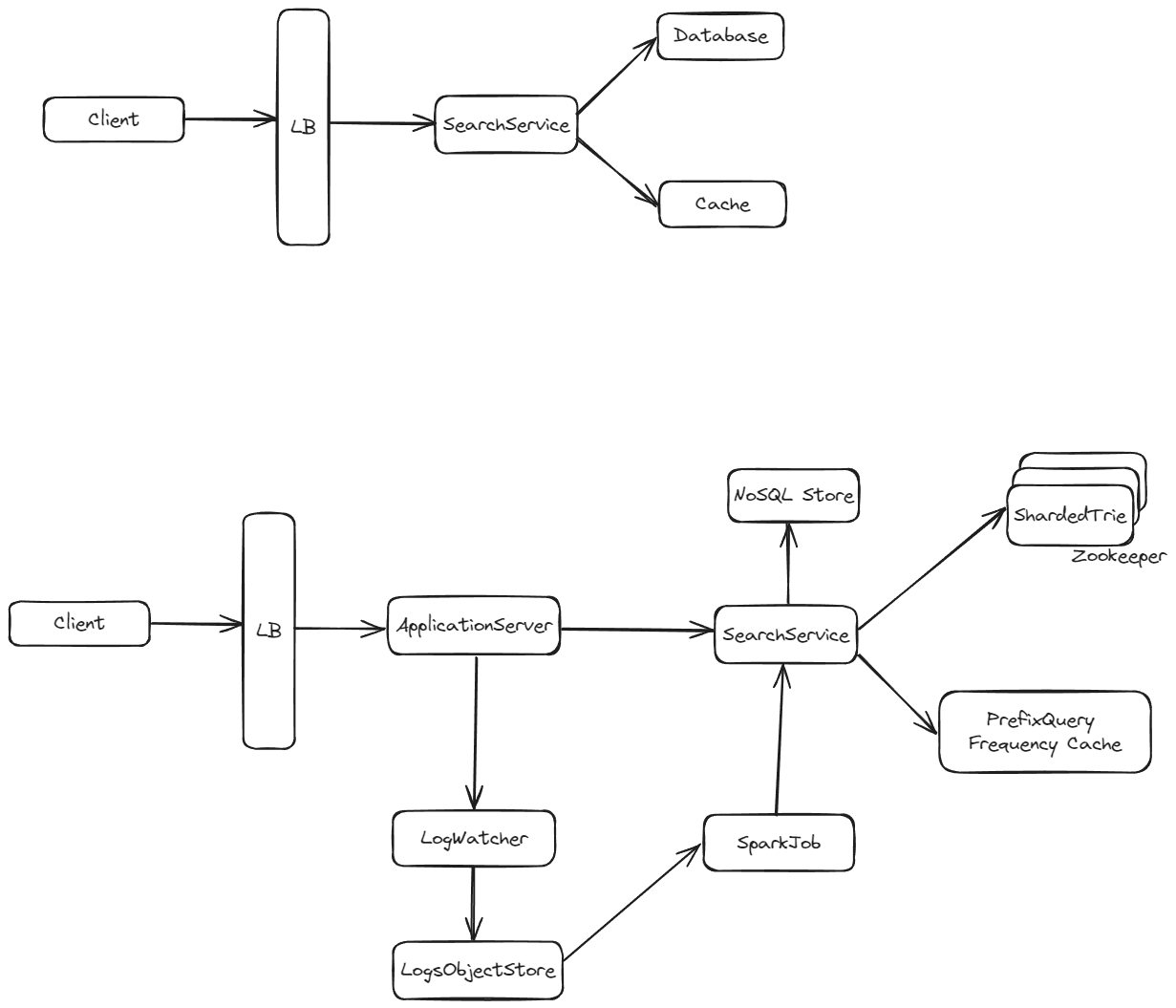
Design Dive Deep
Getting the Top Suggested Queries
Approach 1
- Traverse the Trie and identify the node corresponding to the last character of the prefix.
- After identifying the Trie position with the prefix character, perform a Depth-First Search (DFS) to identify all queries along with their frequencies.
- Filter the top five frequent queries from the resultant set.
Approach 2
- Instead of performing a DFS to identify all the queries, store the top five queries at each node of the Trie.
- Build a hash table storing prefixes as keys and suggestions as values.
- Store the hash table in a cache like Redis for further time optimization in providing suggestions.
Storing the Trie for Persistence
- With each node, store the character it contains and its number of children.
- Place all children of a node immediately after it, as in:
“R2, A2, T2, I, N, G, E, M, O2, L1, L, T”- This format allows for easy reconstruction of the Trie.
Note: We require partition tolerance, availability, and scalability. Hence, NoSQL databases like Cassandra can be used.
Scaling Trie Cache
As we scale, the influx of unique queries may exceed the capacity of a single server. Additionally, sharding the Trie across multiple servers can improve performance as it distributes the load.
- Approach 1:
- Shard based on every character, with each server handling one character.
- This might lead to an imbalance in load.
- Approach 2:
- Start with one server and split the data when it fills or reaches a threshold.
- For example, divide as follows: a-abd | abe-cdx | cdy-eaa, and so on.