



System Design - Design Spotify Music Streaming Platform
Functional Requirements
- As a user, I should be able to search for songs based on the song name/artist name etc.
- As a user, I should be able to play the selected song.
Non-Functional Requirements
- Latency: Low latency is vital for immediate music playback after a user's selection, quick search results, and responsive user interface interactions.
- Scalability: Scalability ensures that as the number of users increases, the system can handle the additional load without performance degradation
- Availability: The users should be able to access music streaming, search functions, and other features without interruptions
- Robustness: Robustness includes the ability to deal with invalid user input, network issues, server failures, and unexpected behavior from client applications.
Capacity Requirements
- Assume that there are around 100 millions songs
- Assume that the size per file is around 5MB.
- Assume that the song metadata size is around 1KB.
This implies that there is a storage requirement of 500 TB to store the song data. Additionally, the storage requirement of the song metadata is around 1 GB.
High Level Design:
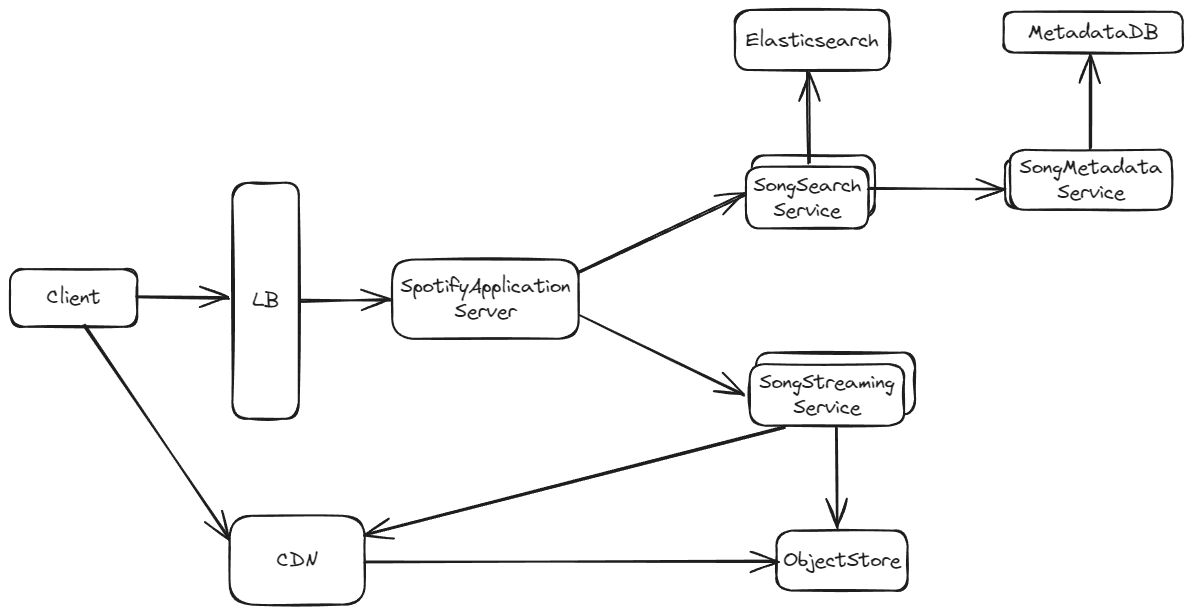
Components:
- SpotifyWebServer: It acts as a BFF that performs authorization, rate limiting and other validations.
- SongSearchService: It is used to return the query result for song search by user
- Elasticsearch: To speed up the search results on song name/artist/lyrics or other metadata, an indexing service like Elasticsearch can be used. This creates an index of all the searchable content, allowing for quick retrieval of search results.
- SongMetadataService: Service that has APIs for getting data from MetadataDB.
- MetadataDB: System of record for the Songs Metadata
- SongStreamingService: It is used to get the song audio file for streaming
- ObjectStore: System of record for the audio filea
- CDN: Content Delivery Network that caches songs for better Latency
Design Dive Deep:
Metadata Datastore
Approach 1: Using Relational Database
Consequences:
- There is already a defined schema for the record stored that may rarely get updated.
- The data can be normalized to store artist, producers, or other information in separate tables which would help reducing data redundancy.
- As there is only a requirement to store 1GB of data, it can easily reside in a single database server.
Approach 2: Using NoSQL Database
Consequences:
- We would have to store redundant data for a song's artist information or other relevant information that is common between multiple songs.
Song
-----------
id: String
name: String
audioURL: StringObject Store
- We can use s3 to store the songs
- We can tiers songs such that less popular songs move to lower tier like S3 Standard-Infrequent Access Storage Class
How Song Streaming Works?
Approach 1: HTTP Range Requests
- For Audio or Video streaming, we can store the file as a whole in blob storage and use HTTP Range Requests to get partial data.
- In case the user has a slower network bandwidth, it can lead to buffering when the partial data is requested with a higher bitrate.
Approach 2: Adaptive Bitrate with HTTP Range Requests
- Store multiple version of an audio file in the object store with varying bitrate.
- The client application starts by fetching a default (lets say 320 kbps) bitrate version. This allows the app to download and play only the initial part of the audio file, reducing the initial load time.
- Concurrently, the appl monitors the user's internet bandwidth. If it detects that the bandwidth is insufficient, it decides to switch to lower bitrate
- This approach requires more manual control and coordination by the app.
Approach 3: HLS or DASH for Adaptive Bitrate Streaming
- In standard Adaptive Streaming Protocols like HLS (HTTP Live Streaming) and DASH (Dynamic Adaptive Streaming over HTTP), the audio/video content is pre-segmented into short chunks, each available in different bitrates.
- The media player reads a manifest file to adaptively select the appropriate segment based on the current network conditions.
NOTE: We can have a hybrid approach to store the manifest and chunks in CDN for popular songs and in S3 for less popular songs. When the client requests for a song to play, the backend service decides based on the popularity and other variables to return the URL of the manifest file from the CDN or S3 in response (only 1 manifest file for all bitrate chunks)
Elasticsearch Failover
- Elasticsearch is not the system of record for the songs metadata. If there is a failure, we can rebuild the cache by using the data in metadata DB.
- Additionally, any update to the Metadata DB will be reflected to the Elasticsearch cluster via an event trigerred on update.