



System Design - Design Shazam an Audio Searching Platform
Functional Requirements
- As a user, I should be able to record an audio and the system should identify return the song from the audio.
Non-Functional Requirements
- Scalability: Shazam must handle a large and potentially unpredictable number of requests from users around the world. Scalability ensures that as the user base grows and request volume increases, the system can handle the additional load without performance degradation.
- Availability: The system should be operational and accessible whenever users attempt to identify a song.
- Latency: Low latency in Shazam's system means that the time from when a user records a sample to when they receive identification should be minimal
- Robustness: Shazam's system should handle and recover from various kinds of failures, such as incorrect song samples, noisy environments, or partial system outages, without crashing or losing functionality. It should also manage a wide variety of music and audio quality and be able to accurately identify songs despite these variables.
Capacity Requirements
- Assume that there are around 100 millions songs
- Assume that the size per file is around 5MB.
- Assume that the song metadata size is around 1KB.
Note: There is no need to store the songs as it could lead to additional storage as well as compliance concerns regarding the rights of the songs. Regarding the storage of the metadata, it will require around 100GB (1KB * 1000 million songs) of storage.
- Assume that a 3 minutes song is divided into 3000 segments of 64 bits each.
This implies that we would require 24KB storage per song in turn would lead to 3TB storage requirements.
Throughput: 100 million daily users with 3 songs search -> 300 million read requests / day -> 3000TPS
High Level Design
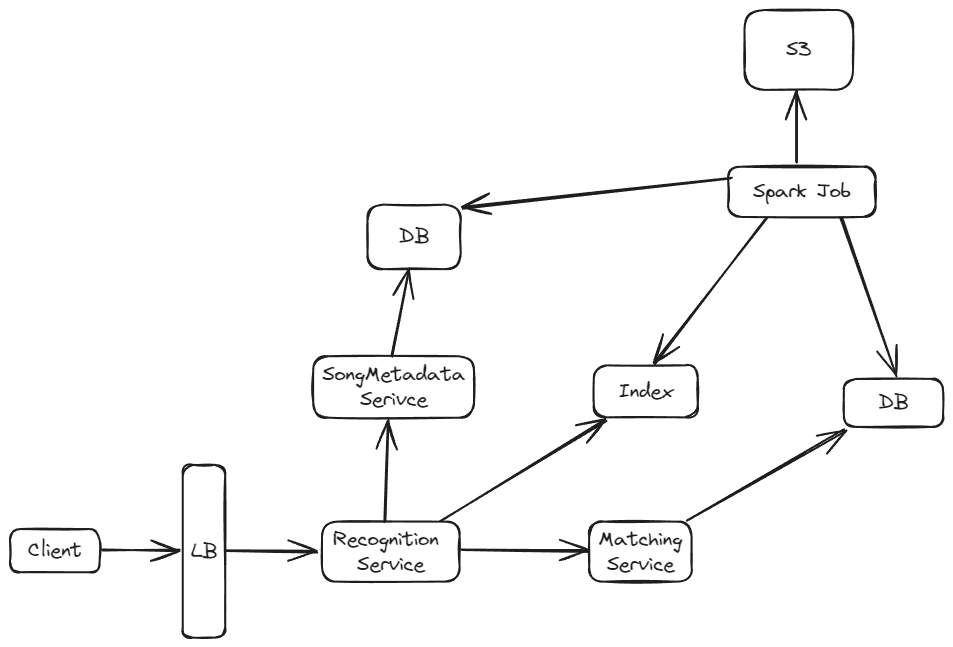
Let's start with identifying how the songs are loaded. When a new song is loaded, it is uploaded to a storage like S3. Additionally, the song metadata is stored in a SQL table.
To generate the segments (fingerprints) from the song, we run a batch job. We can use spark (with AWS Glue or EMR). The generated segments are then stored in a database. Concurrently, we create an inverted index for the fingerprint.
Design Choices
Songs Metadata Database
Approach 1: Using Relational Database
Consequences:
- There is already a defined schema for the record stored that may rarely get updated.
- The data can be normalized to store artist, producers, or other information in separate tables which would help reducing data redundancy.
- As there is only a requirement to store 100GB of data, it can easily reside in a single database server.
Approach 2: Using NoSQL Database
Consequences:
- We would have to store redundant data for a song's artist information or other relevant information that is common between multiple songs.
Song
-----------
id: String
name: String
audioURL: StringNote: Additionally, as it is read-heavy can have a read through cache to store popular songs data in cache.
Songs Fingerprint Database
- There is a requirement to store 3 TB of data.
- There are minimal to no update operation to a single record.
For above reasons, can use a document DB to store the songIds to fingerprints with songID as keys. Additionally, due to data localization will all the fingerprint data stored together, it offer better read performance.
Note: We can add a cache to store popular song indexes.
key = songId
value = List of fingerprints
--------
songId -> List FingerprintsFingerprint Index Storage
- There is a requirement to store 3 TB of data.
- The index needs fast read access
As it needs faster read, we can store the index in memory using Redis. Since the storage requirement is around 3 TB, we would need to shard the data. We can use the fingerprint hash segment as the hash key.
Other option would have been to store the values in disk but that would lead to lower performance.
key = fingerprint
value = List of song ids
--------
fingerprint-> List of song ids