



System Design - Design Pastebin Text Storage System
Functional Requirements
- Users can post plaintext snippets. The system should generate a unique URL for each snippet to facilitate access.
- Snippets can have a predetermined expiration time, after which they become inaccessible.
- Snippets can be public (accessible via URL) or private (accessible only to the creator or through a password).
- Creators can edit or delete their snippets until they expire.
- Users can share snippet URLs across various platforms.
Non-Functional Requirements
- Scalability: The system must scale horizontally to accommodate increasing loads efficiently, handling a high volume of reads and writes.
- Availability: The system should aim for 99.99% uptime, ensuring the created snippets are accessible with high availability.
- Latency: The system should offer low latency for all operations. Reading a snippet should be near real-time. Similarly, the creation, updating, and deletion of snippets should be executed swiftly to ensure a responsive user experience.
- Consistency: The system should maintain strong consistency for individual snippets. Once a snippet is created or updated, all subsequent accesses should reflect the most recent state.
Capacity Requirements
- Assume that on average, each snippet size is around 10 KB with maximum size equal to 10 MB
- Assume there are 1 billion snippets created per month.
- Assume that the read to write ratio is around 5:1
Assuming that the snippet metadata is 1KB per record: 100 bytes/snippet * 1,000,000,000 snippets/month * 12 months = 12,000,000,000 KB, which equals 1.2TB of storage.
With 1 billion snippets per month, and each snippet requiring 10 KB of storage: 10 KB/snippet * 1,000,000,000 snippets/month * 12 months = 120,000,000,000 KB/year, which is equivalent to 120 TB of storage per year.
High Level Design

Design Choices
1. Storing Snippets
Approach 1: Naive - Store contents in DB record
In this approach, the paste content is stored directly in the database. Depending on the requirements, this can be a relational database (e.g., MySQL, PostgreSQL) or a NoSQL database (e.g., MongoDB, DynamoDB).
Pros:
- Managing data within a single system simplifies the architecture.
- Most databases support transactions or atomic operations, which can simplify handling create, update, and delete operations.
- Storing metadata and content in the same database can improve the speed of data retrieval and management.
Cons:
- Large blobs of text can increase the load on the database, potentially impacting performance as the volume of data grows.
- High storage requirements in databases can be more expensive compared to object storage solutions.
- Larger databases complicate backup and recovery processes.
Approach 2: Store Content in S3 (Preferred)
This approach involves storing the paste content in an object storage service like Amazon S3. Only references (e.g., URLs or keys) to the S3 objects are stored in the database.
Pros:
- S3 is highly scalable and can handle large amounts of data without impacting the performance of your primary database.
- S3 provides cost-effective storage, especially for larger objects and data that doesn't require frequent access.
- S3 offers high durability and availability, ensuring data is safe and always accessible.
- Offers built-in features like encryption at rest, access control mechanisms, and compliance certifications.
Cons:
- Requires managing two systems (the database for metadata and S3 for content), which can complicate the architecture.
- Retrieving data from S3 can be slower than from a local database, especially if the internet connectivity or AWS performance issues arise.
- Requires careful handling to ensure consistency between the database records and the actual files stored in S3.
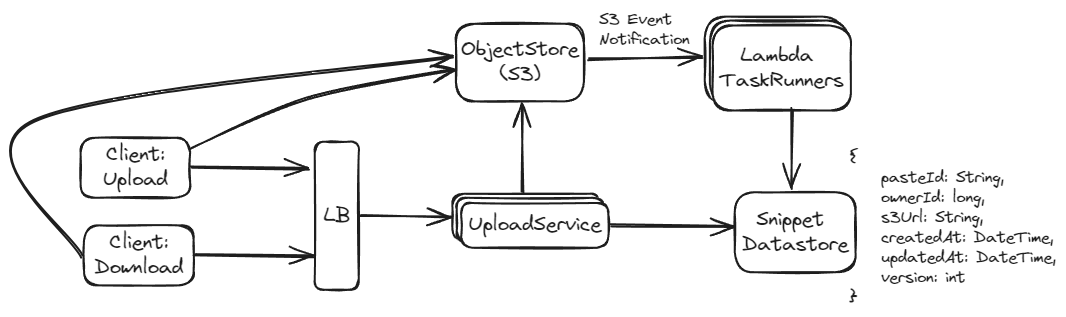
If the expected scale is very large, or if snippets are particularly large, using S3 might be more appropriate due to its scalability and cost benefits. For smaller-scale applications or where latency and complex querying are more critical, a database might be more suitable. For cost-sensitive applications, the lower storage costs of S3 might be more attractive. Using a database alone can simplify the development and maintenance of the application but might not scale as well in the long term compared to a hybrid approach using S3 for storage.
Unique Key Generation
Approach 1: Create an MD5 or SHA-1 Hash of the Content and Use its Prefix
This approach involves generating a hash (e.g., MD5, SHA-1) of the snippet content and using a prefix of the hash (e.g., first 6 characters) as the unique identifier (pasteId) for the snippet.
Pros:
- Easy to implement as it directly ties the key to the content, ensuring that identical contents will always yield the same key.
- Does not require additional storage for managing keys, as the key is derived directly from the content.
Cons:
- Short prefixes can lead to collisions, where different contents yield the same key. This necessitates handling conflicts, which can complicate the system.
- Using content-based hashing exposes the system to potential security risks, such as hash collision attacks.
- When a collision occurs, the system must regenerate a new ID, which involves modifying the content (e.g., adding a random prefix) and recalculating the hash. This increases response times and system complexity.
Approach 2: Use a Separate Key Generation Service (Preferred)
In this method, a dedicated service generates random unique keys (e.g., strings of length 6). These keys are stored in a database, where each key is marked as used once it is allocated to ensure uniqueness.
Pros:
- By controlling key distribution centrally, the system can ensure a very low probability of key collisions, enhancing reliability.
- The key generation service can be scaled independently of the main application, providing flexibility in managing load.
- Randomly generated keys do not expose content and are not susceptible to prediction, enhancing security.
Cons:
- Requires maintaining a database solely for key management, which adds to the infrastructure and maintenance costs.
- Introduces additional complexity in managing another service and ensuring its availability and performance.
- With a fixed length (6 characters), there is a finite limit to the number of unique keys that can be generated. This requires careful planning and potential adjustments as the system scales.
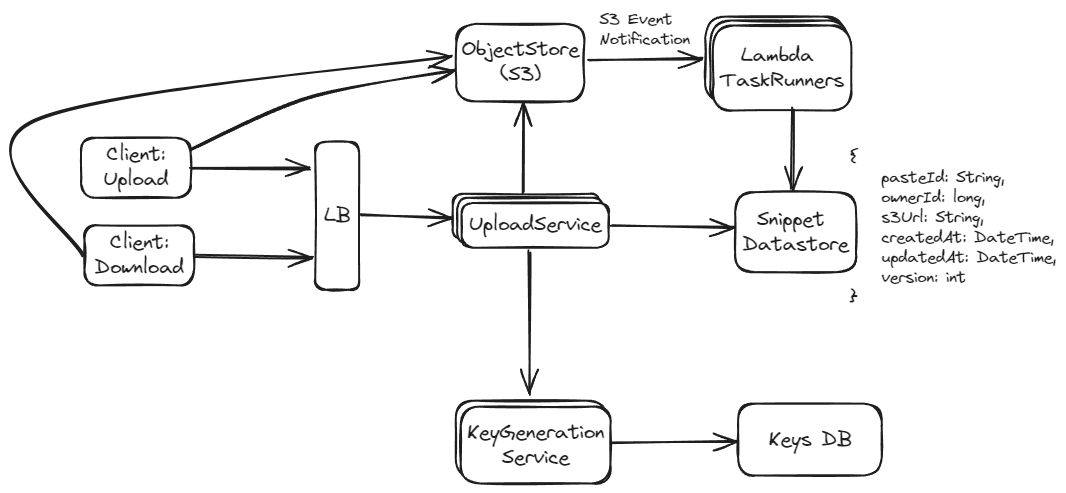
If ensuring the uniqueness of keys with minimal overhead and high security is a priority, Approach 2 might be more suitable despite its higher complexity and operational overhead. It separates key management from content storage, allowing for more robust scalability and security measures. On the other hand, Approach 1 could be sufficient for systems with lower security concerns and less stringent requirements on key collision handling. It offers a simple and direct method of generating identifiers but requires careful handling of potential hash collisions, especially as the system scales.
3. Expiration of Content
Approach 1: Cron Task Runner Service to Check Expiration in Database
In this approach, a scheduled task (cron job) periodically scans the database to identify and handle expired content. This might involve flagging content as expired, deleting it, or performing other cleanup activities.
Pros:
- Allows for complex logic during the expiration check, such as notifying users, logging information, or other custom actions.
- Gives full control over the timing and frequency of checks, and can be adjusted based on system performance and requirements.
- Easy to understand and implement, especially in environments where a cron job setup is already available.
Cons:
- As data grows, the task of scanning the database can become resource-intensive and slow, potentially affecting database performance during peak times.
- Expiration checks are only as frequent as the cron job runs, which might not be immediate and can lead to expired content being accessible past its intended lifetime.
- Periodic checks consume system resources regardless of whether there is expired content, which can be inefficient in systems with variable expiration activities.
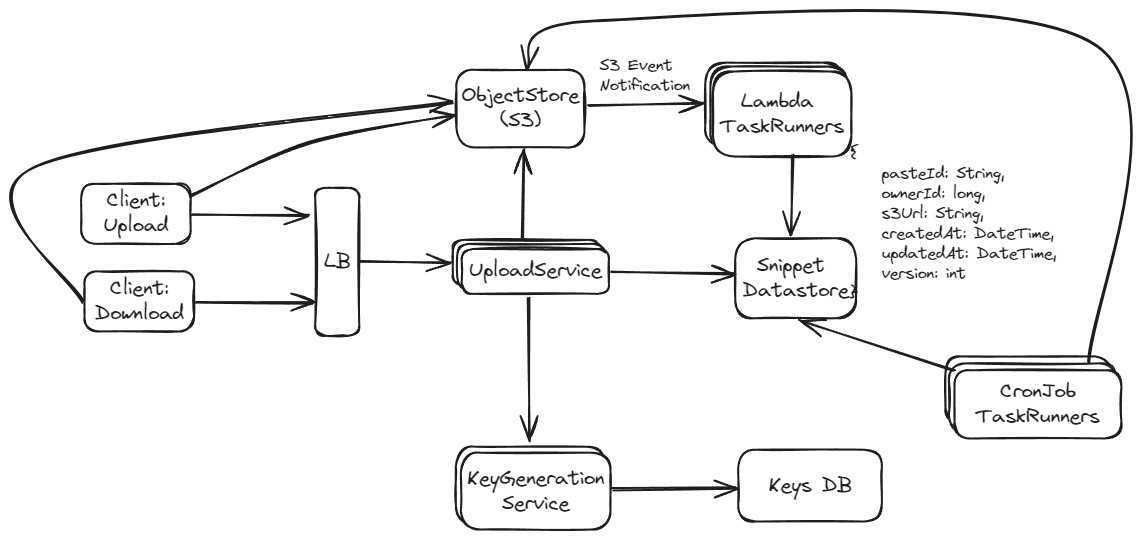
Approach 2: DynamoDB TTL with DynamoDB Streams
This approach leverages DynamoDB's Time to Live (TTL) feature, where items are automatically deleted after a certain time. DynamoDB Streams can then capture these deletion events, and a linked AWS Lambda function can perform additional actions, like cleaning up related records in other databases or systems.
Pros:
- TTL is handled natively by DynamoDB, which can efficiently manage and automatically delete expired items without impacting database performance.
- Deletion events are captured in real-time by DynamoDB Streams, allowing immediate downstream actions via Lambda.
- This method scales well with the database size and activity, as TTL deletions and stream processing are managed by AWS services designed for high throughput and low latency.
Cons:
- The TTL mechanism only deletes the item; it does not allow for items to be flagged as expired if the use case requires maintaining the record for historical reasons or audits.
- Involves setting up and managing multiple AWS services (DynamoDB, DynamoDB Streams, and Lambda), which can add complexity to the architecture.
- This approach ties the system to AWS-specific technologies, which might not be suitable for systems aiming for provider independence or those using a multi-cloud strategy.
For larger, scalable applications where managing resources efficiently is critical, and the application is already hosted on AWS, Approach 2 is generally more effective. For smaller applications, or where custom expiration actions are needed that go beyond simple deletion, Approach 1 might be more appropriate, despite its potential scalability and efficiency issues.