



System Design - Design a URL Shortener
Functional Requirements
- As a user, I should be able to input a URL and retrieve a shortened URL.
- As a user, when I enter the shortened URL in a browser, it should redirect me to the original URL location.
- As a system, I should expire and clean up old URLs.
- As a system, I should store the analytics usage information of the URLs, including clicks, locations, referrers, etc.
- As a system, I should allow users to generate custom shortened URLs.
Non-Functional Requirements
- Availability: High availability is crucial because users and automated systems expect short links to redirect to their long URL counterparts at all times. This often involves redundant infrastructure, failover mechanisms, and possibly multi-region deployment to withstand regional outages.
- Scalability: Horizontal scalability is often more relevant, as you would need to handle large volumes of requests and data. This includes scaling the database to store the increasing number of URLs and scaling the web servers to handle the increasing request load.
- Latency: Low latency is critical because users expect immediate redirection from the shortened URL to the original URL.
- Robustness: Handling invalid inputs gracefully, maintaining service during network failures, server crashes, and managing unexpected surges in traffic.
Capacity Requirements
- Assume there are 500 million URLs generated per month.
- Assume that there is a 100:1 read to write ratio.
- Assume that it takes around 500 bytes to store the content for a single URL.
This implies that it requires 250GB storage per month for URL storage. Additionally, to store each shorten URL key (6 bytes each), it requires a total of 3GB storage.
High Level Design
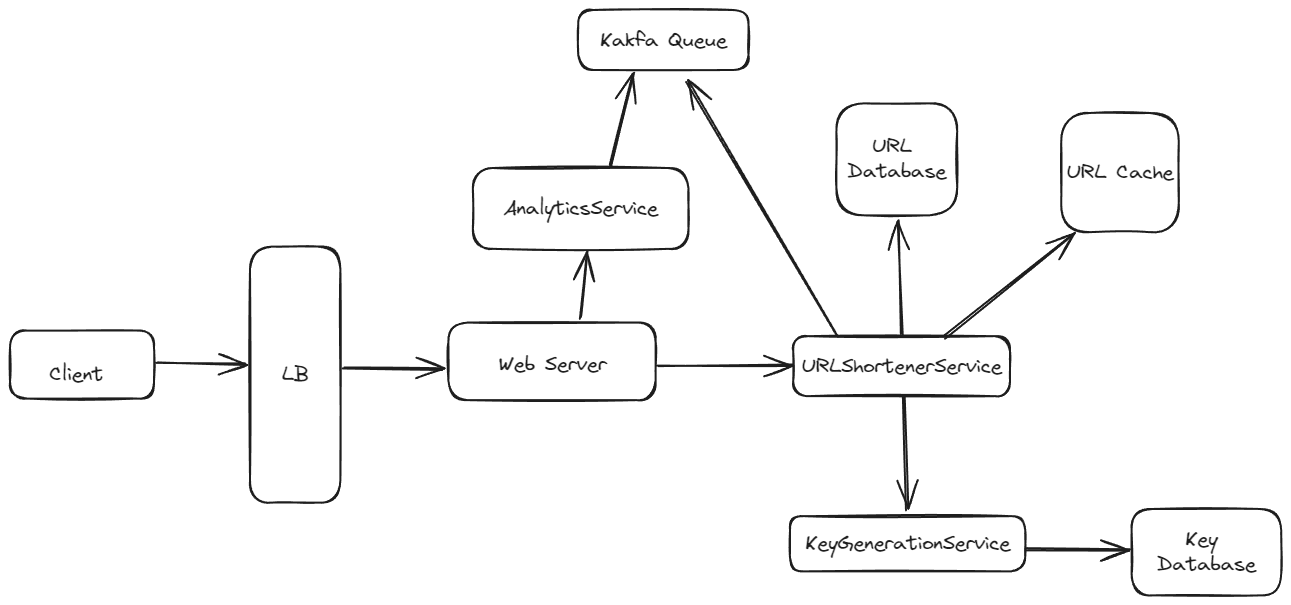
Components
- Load Balancer - Used to balance load to the Web Server instances.
- Web Server - It is a backend for front-end service that is the single point of contact of all the incoming request from the client. These requests after proper authentication/authorization are redirected to the different microservices.
- URLShortenerService - Service that hosts APIs to shorten the URL as well as returning the original URL from a shorten URL.
- KeyGenerationService - Service that is responsible for generating and returning a key being used by the URL shortener.
- KeyDatabase - Database to store the generated keys
- URL Database - Database to store the longURL to short URL Mapping
- Analytics Service - Service to store and access analytics data
Design Dive Deep
Key Generation
Approach 1: Generate Hash value of each long URL
This approach requires generating md5 or sha-256 of long URL and split first 6 characters of the URL.
Consequences:
- Pros:
- Easy to integrate a library to generate hash value
- Cons:
- It can lead to collisions as multiple the fist 6 characters of multiple hash values can be same.
Note: To resolve these collisions, we can check in the datastore if the key already exists. If it does not, we can use the generated key and store it in the DB. Otherwise, we can recursively add some predefined string to the original URL as a prefix until a unique key is generated. However, this will lead to an increase in latency and could also put a load on the database.
Approach 2: Use base62 encoder with a sequence number
This approach involved using a base62 encoder with a sequence number. The unique sequence number will be the auto-increment id of the Database entry of the long-URL.
Consequences:
- Pros:
- There will be no collisions as the auto-increments Id will be unique.
- Cons:
- It will be easy to predict other URLs that can lead to some security concern.
Approach 3: Offline URL Generation
This approach requires generating a random string of length 6 and storing it in a database. Whenever there is a request to generate a new shortened URL, we can choose a key and mark the record as used once the key is returned to the upstream.
Consequences:
- Pros:
- There will be no collisions as the id will be unique.
- Cons:
- We need to handle concurrency issue when multiple upstream calls fetches same string.
Database Strategy:
Approach 1: Using Relational Database
Consequences:
- Pros:
- There is already a defined schema for the record stored that may rarely get updated.
- Cons:
- As we need to store billion of records, it will be difficult to store in a single relational DB.
- To scale the database, we would need to partition it which will add additional infrastructure overhead.
Approach 2: Using NoSQL Database
Consequences:
- Pros:
- There is no relationship between records. Thus, there will be no requirements to perform complex queries and joins.
- We can store huge number of records with sharding. faster read heavy
- Cons:
- We already have a defined schema.
Frequently Asked Questions
How will you extend the design to support analytics?
WIP